Publications¶
Book chapters¶
Performance Tuning for Tile-Based Architectures¶

Bruce Merry. Performance tuning for tile-based architectures. In Patrick Cozzi and Christophe Riccio, editors, OpenGL Insights, pages 323–336. CRC Press, 2012.
Introduction¶
In this chapter, we will examine tile-based rendering, a particular way to arrange a graphics pipeline that is used in several popular mobile GPUs. We will look at what tile-based rendering is and why it is used and then look at what needs to be done differently to achieve optimal performance. I assume that the reader already has experience with optimizing OpenGL applications and is familiar with the standard techniques, such as reducing state changes, reducing the number of draw calls, reducing shader complexity and texture compression, and is looking for advice that is specific to tile-based GPUs.
Papers — radio astronomy¶
Efficient channelization on a graphics processing unit¶
Bruce Merry. Efficient channelization on a graphics processing unit. J. Astron. Telesc. Instrum. Syst. 9(3) 038001, 2023.
Abstract¶
We present an implementation of a channelizer (F-engine) running on a graphics processing unit (GPU). While not the first GPU implementation of a channelizer, we have put significant effort into optimizing the implementation. We are able to process 4 antennas each with 2 Gsample/s, 10-bit dual-polarized input and 8-bit output, on a single commodity GPU. This fully utilizes the available peripheral component interconnect express (PCIe) bandwidth of the GPU. The system is not as optimized for a single high-bandwidth antenna but handles 6.2 Gsample/s, limited by single-core central processing unit (CPU) performance.
Prospects of GPU Tensor Core Correlation for the SMA and the ngEHT¶
Wei Yu et al. Prospects of GPU Tensor Core Correlation for the SMA and the ngEHT. Galaxies 11, no. 1: 13, 2023.
Abstract¶
Building on the base of the existing telescopes of the Event Horizon Telescope (EHT) and ALMA, the next-generation EHT (ngEHT) aspires to deploy ∼10 more stations. The ngEHT targets an angular resolution of ∼15 microarcseconds. This resolution is achieved using Very Long Baseline Interferometry (VLBI) at the shortest radio wavelengths ∼1 mm. The Submillimeter Array (SMA) is both a standalone radio interferometer and a station of the EHT and will conduct observations together with the new ngEHT stations. The future EHT + ngEHT array requires a dedicated correlator to process massive amounts of data. The current correlator-beamformer (CBF) of the SMA would also benefit from an upgrade, to expand the SMA’s bandwidth and also match the EHT + ngEHT observations. The two correlators share the same basic architecture, so that the development time can be reduced using common technology for both applications. This paper explores the prospects of using Tensor Core Graphics Processing Units (TC GPU) as the primary digital signal processing (DSP) engine. This paper describes the architecture, aspects of the detailed design, and approaches to performance optimization of a CBF using the “FX” approach. We describe some of the benefits and challenges of the TC GPU approach.
The Astropy Project: Sustaining and Growing a Community-oriented Open-source Project and the Latest Major Release (v5.0) of the Core Package¶
Adrian M Price-Whelan et al. The Astropy Project: Sustaining and Growing a Community-oriented Open-source Project and the Latest Major Release (v5.0) of the Core Package. Astrophysical Journal, 935(2), p. 167, 2022.
Abstract¶
The Astropy Project supports and fosters the development of open-source and openly developed Python packages that provide commonly needed functionality to the astronomical community. A key element of the Astropy Project is the core package astropy, which serves as the foundation for more specialized projects and packages. In this article, we summarize key features in the core package as of the recent major release, version 5.0, and provide major updates on the Project. We then discuss supporting a broader ecosystem of interoperable packages, including connections with several astronomical observatories and missions. We also revisit the future outlook of the Astropy Project and the current status of Learn Astropy. We conclude by raising and discussing the current and future challenges facing the Project.
The 1.28 GHz MeerKAT Galactic Center Mosaic¶
I. Heywood et al. The 1.28 GHz MeerKAT Galactic Center Mosaic. Astrophysical Journal, 925(2), p. 165, 2022.
Abstract¶
The inner ∼200 pc region of the Galaxy contains a 4 million M☉ supermassive black hole (SMBH), significant quantities of molecular gas, and star formation and cosmic-ray energy densities that are roughly two orders of magnitude higher than the corresponding levels in the Galactic disk. At a distance of only 8.2 kpc, the region presents astronomers with a unique opportunity to study a diverse range of energetic astrophysical phenomena, from stellar objects in extreme environments, to the SMBH and star-formation-driven feedback processes that are known to influence the evolution of galaxies as a whole. We present a new survey of the Galactic center conducted with the South African MeerKAT radio telescope. Radio imaging offers a view that is unaffected by the large quantities of dust that obscure the region at other wavelengths, and a scene of striking complexity is revealed. We produce total-intensity and spectral-index mosaics of the region from 20 pointings (144 hr on-target in total), covering 6.5 square degrees with an angular resolution of 4″ at a central frequency of 1.28 GHz. Many new features are revealed for the first time due to a combination of MeerKAT’s high sensitivity, exceptional u, v-plane coverage, and geographical vantage point. We highlight some initial survey results, including new supernova remnant candidates, many new nonthermal filament complexes, and enhanced views of the Radio Arc bubble, Sagittarius A, and Sagittarius B regions. This project is a South African Radio Astronomy Observatory public legacy survey, and the image products are made available with this article.
The MeerKAT Galaxy Cluster Legacy Survey — I. Survey Overview and Highlights¶
PDF (pre-print) | publisher’s page | Data
K. Knowles et al. The MeerKAT Galaxy Cluster Legacy Survey — I. Survey Overview and Highlights. Astronomy and Astrophysics 657 A56, 2022.
Abstract¶
MeerKAT’s large number (64) of 13.5 m diameter antennas, spanning 8 km with a densely packed 1 km core, create a powerful instrument for wide-area surveys, with high sensitivity over a wide range of angular scales. The MeerKAT Galaxy Cluster Legacy Survey (MGCLS) is a programme of long-track MeerKAT L-band (900−1670 MHz) observations of 115 galaxy clusters, observed for ~6−10 h each in full polarisation. The first legacy product data release (DR1), made available with this paper, includes the MeerKAT visibilities, basic image cubes at ~8″ resolution, and enhanced spectral and polarisation image cubes at ~8″ and 15″ resolutions. Typical sensitivities for the full-resolution MGCLS image products range from ~3−5 μJy beam−1. The basic cubes are full-field and span 2° × 2°. The enhanced products consist of the inner 1.2° × 1.2° field of view, corrected for the primary beam. The survey is fully sensitive to structures up to ~10′ scales, and the wide bandwidth allows spectral and Faraday rotation mapping. Relatively narrow frequency channels (209 kHz) are also used to provide H I mapping in windows of 0 < z < 0.09 and 0.19 < z < 0.48. In this paper, we provide an overview of the survey and the DR1 products, including caveats for usage. We present some initial results from the survey, both for their intrinsic scientific value and to highlight the capabilities for further exploration with these data. These include a primary-beam-corrected compact source catalogue of ~626 000 sources for the full survey and an optical and infrared cross-matched catalogue for compact sources in the primary-beam-corrected areas of Abell 209 and Abell S295. We examine dust unbiased star-formation rates as a function of cluster-centric radius in Abell 209, extending out to 3.5 R200. We find no dependence of the star-formation rate on distance from the cluster centre, and we observe a small excess of the radio-to-100 μm flux ratio towards the centre of Abell 209 that may reflect a ram pressure enhancement in the denser environment. We detect diffuse cluster radio emission in 62 of the surveyed systems and present a catalogue of the 99 diffuse cluster emission structures, of which 56 are new. These include mini-halos, halos, relics, and other diffuse structures for which no suitable characterisation currently exists. We highlight some of the radio galaxies that challenge current paradigms, such as trident-shaped structures, jets that remain well collimated far beyond their bending radius, and filamentary features linked to radio galaxies that likely illuminate magnetic flux tubes in the intracluster medium. We also present early results from the H I analysis of four clusters, which show a wide variety of H I mass distributions that reflect both sensitivity and intrinsic cluster effects, and the serendipitous discovery of a group in the foreground of Abell 3365.
The 1.28 GHz MeerKAT DEEP2 Image¶
T. Mauch et al. The 1.28 GHz MeerKAT DEEP2 Image. Astrophysical Journal, 888(2), p. 61, 2020.
Abstract¶
We present the confusion-limited 1.28 GHz MeerKAT DEEP2 image covering one \(\theta_b \approx 68'\) FWHM primary beam area with \(\theta = 7.6''\) FWHM resolution and \(\sigma_n = 0.55 \pm 0.01\) µJy/beam rms noise. Its J2000 center position \(\alpha=04^h 13^m 26.4^s\), \(\delta=-80^\circ 00' 00''\) was selected to minimize artifacts caused by bright sources. We introduce the new 64-element MeerKAT array and describe commissioning observations to measure the primary beam attenuation pattern, estimate telescope pointing errors, and pinpoint \((u,v)\) coordinate errors caused by offsets in frequency or time. We constructed a 1.4 GHz differential source count by combining a power-law count fit to the DEEP2 confusion \(P(D)\) distribution from 0.25 to 10 µJy with counts of individual DEEP2 sources between 10 µJy and 2.5 mJy. Most sources fainter than \(S \sim 100\) µJy are distant star-forming galaxies obeying the FIR/radio correlation, and sources stronger than 0.25 µJy account for \(\sim93\%\) of the radio background produced by star-forming galaxies. For the first time, the DEEP2 source count has reached the depth needed to reveal the majority of the star formation history of the universe. A pure luminosity evolution of the 1.4 GHz local luminosity function consistent with the Madau & Dickinson (2014) model for the evolution of star-forming galaxies based on UV and infrared data underpredicts our 1.4 GHz source count in the range \(-5 \lesssim \log[S(\mathrm{Jy})] \lesssim -4\).
Inflation of 430-parsec bipolar radio bubbles in the Galactic Centre by an energetic event¶
I. Heywood et al. Inflation of 430-parsec bipolar radio bubbles in the Galactic Centre by an energetic event. Nature, 573, p. 235-237, 2019.
Abstract¶
The Galactic Centre contains a supermassive black hole with a mass of four million Suns within an environment that differs markedly from that of the Galactic disk. Although the black hole is essentially quiescent in the broader context of active galactic nuclei, X-ray observations have provided evidence for energetic outbursts from its surroundings. Also, although the levels of star formation in the Galactic Centre have been approximately constant over the past few hundred million years, there is evidence of increased short-duration bursts, strongly influenced by the interaction of the black hole with the enhanced gas density present within the ring-like central molecular zone at Galactic longitude |l| < 0.7 degrees and latitude |b| < 0.2 degrees. The inner 200-parsec region is characterized by large amounts of warm molecular gas, a high cosmic-ray ionization rate, unusual gas chemistry, enhanced synchrotron emission, and a multitude of radio-emitting magnetized filaments, the origin of which has not been established. Here we report radio imaging that reveals a bipolar bubble structure, with an overall span of 1 degree by 3 degrees (140 parsecs × 430 parsecs), extending above and below the Galactic plane and apparently associated with the Galactic Centre. The structure is edge-brightened and bounded, with symmetry implying creation by an energetic event in the Galactic Centre. We estimate the age of the bubbles to be a few million years, with a total energy of 7 × 1052 ergs. We postulate that the progenitor event was a major contributor to the increased cosmic-ray density in the Galactic Centre, and is in turn the principal source of the relativistic particles required to power the synchrotron emission of the radio filaments within and in the vicinity of the bubble cavities.
Revival of the Magnetar PSR J1622–4950: Observations with MeerKAT, Parkes, XMM-Newton, Swift, Chandra, and NuSTAR¶
F. Camilo et al. Revival of the Magnetar PSR J1622-4950: Observations with MeerKAT, Parkes, XMM-Newton, Swift, Chandra, and NuSTAR. Astrophysical Journal, 856(2), p. 180, 2018.
Abstract¶
New radio (MeerKAT and Parkes) and X-ray (XMM-Newton, Swift, Chandra, and NuSTAR) observations of PSR J1622–4950 indicate that the magnetar, in a quiescent state since at least early 2015, reactivated between 2017 March 19 and April 5. The radio flux density, while variable, is approximately 100× larger than during its dormant state. The X-ray flux one month after reactivation was at least 800× larger than during quiescence, and has been decaying exponentially on a 111 ± 19 day timescale. This high-flux state, together with a radio-derived rotational ephemeris, enabled for the first time the detection of X-ray pulsations for this magnetar. At 5%, the 0.3–6 keV pulsed fraction is comparable to the smallest observed for magnetars. The overall pulsar geometry inferred from polarized radio emission appears to be broadly consistent with that determined 6–8 years earlier. However, rotating vector model fits suggest that we are now seeing radio emission from a different location in the magnetosphere than previously. This indicates a novel way in which radio emission from magnetars can differ from that of ordinary pulsars. The torque on the neutron star is varying rapidly and unsteadily, as is common for magnetars following outburst, having changed by a factor of 7 within six months of reactivation.
Faster GPU-based convolutional gridding via thread coarsening¶

BibTeX
| publisher’s page
| PDF
Bruce Merry. Faster GPU-based convolutional gridding via thread coarsening. Astronomy and Computing, Vol 16, pp 140-145, 2016.
Abstract¶
Convolutional gridding is a processor-intensive step in interferometric imaging. While it is possible to use graphics processing units (GPUs) to accelerate this operation, existing methods use only a fraction of the available flops. We apply thread coarsening to improve the efficiency of an existing algorithm, and observe performance gains of up to 3.2× for single-polarization gridding and 1.9× for quad-polarization gridding on a GeForce GTX 980, and smaller but still significant gains on a Radeon R9 290X.
Approximating W projection as a separable kernel¶

BibTeX
| publisher’s page
| PDF
Bruce Merry. Approximating W projection as a separable kernel. Monthly Notices of the Royal Astronomical Society, 456(2), pp. 1761-1766, 2016.
Abstract¶
W projection is a commonly used approach to allow interferometric imaging to be accelerated by fast Fourier transforms, but it can require a huge amount of storage for convolution kernels. The kernels are not separable, but we show that they can be closely approximated by separable kernels. The error scales with the fourth power of the field of view, and so is small enough to be ignored at mid- to high frequencies. We also show that hybrid imaging algorithms combining W projection with either faceting, snapshotting, or W stacking allow the error to be made arbitrarily small, making the approximation suitable even for high-resolution wide-field instruments.
Papers — computer graphics and GPU computing¶
A performance comparison of sort and scan libraries for GPUs¶

BibTeX
| PDF
| publisher’s page
| software
(electronic version of an article published as Parallel Processing Letters, 25, 4, 2015, 1550007 10.1142/S0129626415500073 © copyright World Scientific Publishing Company http://www.worldscientific.com/worldscinet/ppl)
Bruce Merry. A performance comparison of sort and scan libraries for GPUs. Parallel Processing Letters, 25(4), pp. 1550007, Dec 2015.
Abstract¶
Sorting and scanning are two fundamental primitives for constructing highly parallel algorithms. A number of libraries now provide implementations of these primitives for GPUs, but there is relatively little information about the performance of these implementations.
We benchmark seven libraries for 32-bit integer scan and sort, and sorting 32-bit values by 32-bit integer keys. We show that there is a large variation in performance between the libraries, and that no one library has both optimal performance and portability.
Moving least-squares reconstruction of large models with GPUs¶

Bruce Merry, James Gain and Patrick Marais. Moving least-squares reconstruction of large models with GPUs. IEEE Transactions on Visualization and Computer Graphics, 20(2), pp. 249–261, Feb 2014.
BibTeX
| paper
| appendix
| software
This is the author’s version of the work. The preprint can also be obtained from IEEE Xplore.
Abstract¶
Modern laser range scanning campaigns produce extremely large point clouds, and reconstructing a triangulated surface thus requires both out-of-core techniques and significant computational power. We present a GPU-accelerated implementation of the Moving Least Squares (MLS) surface reconstruction technique. We believe this to be the first GPU-accelerated, out-of-core implementation of surface reconstruction that is suitable for laser range-scanned data. While several previous out-of-core approaches use a sweep-plane approach, we subdivide the space into cubic regions that are processed independently. This independence allows the algorithm to be parallelized using multiple GPUs, either in a single machine or a cluster. It also allows data sets with billions of point samples to be processed on a standard desktop PC. We show that our implementation is an order of magnitude faster than a CPU-based implementation when using a single GPU, and scales well to 8 GPUs.
Fast in-place binning of laser range-scanned point sets¶

Bruce Merry, James Gain and Patrick Marais. Fast in-place binning of laser range-scanned point sets. Journal on Computing and Cultural Heritage, 6, 3, Article 14, July 2013.
This is the author’s version of the work. It is posted here by permission of ACM for your personal use. Not for redistribution. The definitive version was published in the Journal on Computing and Cultural Heritage, 6, 3, Article 14 (July 2013), http://doi.acm.org/10.1145/2499931.2499935.
Abstract¶
Laser range scanning is commonly used in cultural heritage to create digital models of real-world artefacts. A large scanning campaign can produce billions of point samples — too many to be manipulated in memory on most computers. It is thus necessary to spatially partition the data so that it can be processed in bins or slices. We introduce a novel compression mechanism that exploits spatial coherence in the data to allow the bins to be computed with only 1.01 bytes of I/O traffic for each byte of input, compared to 2 or more for previous schemes. Additionally, the bins are loaded from the original files for processing rather than from a sorted copy, thus minimising disk space requirements. We demonstrate that our method yields performance improvements in a typical point-processing task, while also using little memory and guaranteeing an upper bound on the number of samples held in-core.
Accelerating kd-tree searches for all k-nearest neighbours¶

Bruce Merry, James Gain and Patrick Marais. Accelerating kd-tree searches for all k-nearest neighbours. In Eurographics 2013 — Short Papers. 2013.
BibTeX
| paper
| tech report
The definitive version is available at http://diglib.eg.org.
Abstract¶
Finding the k nearest neighbours of each point in a point cloud forms an integral part of many point-cloud processing tasks. One common approach is to build a kd-tree over the points and then iteratively query the k nearest neighbors of each point. We introduce a simple modification to these queries to exploit the coherence between successive points; no changes are required to the kd-tree data structure. The path from the root to the appropriate leaf is updated incrementally, and backtracking is done bottom-up. We show that this can reduce the time to compute the neighbourhood graph of a 3D point cloud by over 10%, and by up to 24% when k = 1. The gains scale with the depth of the kd-tree, and the method is suitable for parallel implementation.
Analytic simplification of animated characters¶

Bruce Merry, Patrick Marais and James Gain. Analytic simplification of animated characters. In Proceedings of the 6th international conference on Computer graphics, virtual reality, visualisation and interaction in Africa (Afrigraph 2009), pages 37–45.
This is an author-prepared version of the document, posted by permission of the ACM for your personal use. It is not for redistribution.
Abstract¶
Traditionally, levels of detail (LOD) for animated characters are computed from a single pose. Later techniques refined this approach by considering a set of sample poses and evaluating a more representative error metric. A recent approach to the character animation problem, animation space, provides a framework for measuring error analytically. The work presented here uses the animation-space framework to derive two new techniques to improve the quality of LOD approximations.
Firstly, we use an animation-space distance metric within a progressive mesh-based LOD scheme, giving results that are reasonable across a range of poses, without requiring that the pose space be sampled.
Secondly, we simplify individual vertices by reducing the number of bones that influence them, using a constrained least-squares optimisation. This influence simplification is combined with the progressive mesh to form a single stream of simplifications. Influence simplification reduces the geometric error by up to an order of magnitude, and allows models to be simplified further than is possible with only a progressive mesh.
A comparison of linear skinning techniques for character animation¶
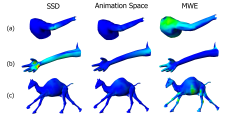
David Jacka, Ashley Reid, Bruce Merry and James Gain. A comparison of linear skinning techniques for character animation. In AFRIGRAPH ‘07: Proceedings of the 5th international conference on Computer graphics, virtual reality, visualisation and interaction in Africa, pages 177–186.
Abstract¶
Character animation is the task of moving a complex, artificial character in a life-like manner. A widely used method for character animation involves embedding a simple skeleton within a character model and then animating the character by moving the underlying skeleton. The character’s skin is required to move and deform along with the skeleton. Research into this problem has resulted in a number of skinning frameworks. There has, however, been no objective attempt to compare these methods.
We compare three linear skinning frameworks that are computationally efficient enough to be used for real-time animation: Skeletal Subspace Deformation, Animation Space and Multi-Weight Enveloping. These create a correspondence between the points on a character’s skin and the underlying skeleton by means of a number of weights, with more weights providing greater flexibility.
The quality of each of the three frameworks is tested by generating the skins for a number of poses for which the ideal skin is known. These generated skin meshes are then compared to the ideal skins using various mesh comparison techniques and human studies are used to determine the effect of any temporal artefacts introduced. We found that SSD lacks flexibility while Multi-Weight Enveloping is prone to overfitting. Animation Space consistently outperforms the other two frameworks.
Animation space: a truly linear framework for character animation¶

Bruce Merry, Patrick Marais and James Gain. Animation space: A truly linear framework for character animation. ACM Trans. Graph. 25, 4 (Oct. 2006), 1400–1423.
This is an author-prepared version of the document, posted by permission of the ACM for your personal use. It is not for redistribution.
Abstract¶
Skeletal subspace deformation (SSD), a simple method of character animation used in many applications, has several shortcomings; the best-known is that joints tend to collapse when bent. We present animation space, a generalization of SSD that greatly reduces these effects and effectively eliminates them for joints that do not have an unusually large range of motion.
While other, more expensive generalizations exist, ours is unique in expressing the animation process as a simple linear transformation of the input coordinates. We show that linearity can be used to derive a measure of average distance (across the space of poses), and apply this to improving parametrizations.
Linearity also makes it possible to fit a model to a set of examples using least-squares methods. The extra generality in animation space allows for a good fit to realistic data, and overfitting can be controlled to allow fitted models to generalize to new poses. Despite the extra vertex attributes, it is possible to render these animation-space models in hardware with no loss of performance relative to SSD.
Normal transformations for articulated models¶

Merry B., Marais P. and Gain J. Normal Transformations for Articulated models. In ACM SIGGRAPH 2006 Conference Abstracts and Applications, August 2006.
BibTeX
| paper
| video
| tech report
These are provided for personal use and may not be publicly redistributed.
Abstract¶
It is well-established that when a matrix is used to transform a rigid object, the normals should be transformed by the inverse transpose of that matrix. For skeletally animated models, it is common to apply this approach to the blended matrix that animates each vertex. This is only an approximation, as it assumes that the blended matrix is locally constant. We derive a correct method for normal transformation in skeletally animated models, and examine the errors introduced by two approximations.
Compression of dense and regular point clouds¶

Merry B., Marais P. and Gain J. Compression of dense and regular point clouds. In AFRIGRAPH 2006: Proceedings of the 4th international conference on Computer graphics, virtual reality, visualisation and interaction in Africa, pages 15–20.
BibTeX
| paper
| video
| software
Merry B., Marais P. and Gain J. Compression of dense and regular point clouds.
Computer Graphics Forum 25, 4 (Dec. 2006), 709–716.
BibTeX
This is an author-prepared version of the document, posted by permission of the ACM for your personal use. It is not for redistribution.
Abstract¶
We present a simple technique for single-rate compression of point clouds sampled from a surface, based on a spanning tree of the points. Unlike previous methods, we predict future vertices using both a linear predictor, which uses the previous edge as a predictor for the current edge, and lateral predictors that rotate the previous edge 90° left or right about an estimated normal.
By careful construction of the spanning tree and choice of prediction rules, our method improves upon existing compression rates when applied to regularly sampled point sets, such as those produced by laser range scanning or uniform tesselation of higher-order surfaces. For less regular sets of points, the compression rate is still generally within 1.5 bits per point of other compression algorithms.
PhD thesis¶
A linear framework for character animation¶
Merry, B. A linear framework for character animation. PhD thesis, University of Cape Town, 2007.
Abstract¶
Character animation is the process of modelling and rendering a mobile character in a virtual world. It has numerous applications both off-line, such as virtual actors in films, and real-time, such as in games and other virtual environments. There are a number of algorithms for determining the appearance of an animated character, with different trade-offs between quality, ease of control, and computational cost. We introduce a new method, animation space, which provides a good balance between the ease-of-use of very simple schemes and the quality of more complex schemes, together with excellent performance. It can also be integrated into a range of existing computer graphics algorithms.
Animation space is described by a simple and elegant linear equation. Apart from making it fast and easy to implement, linearity facilitates mathematical analysis. We derive two metrics on the space of vertices (the “animation space”), which indicate the mean and maximum distances between two points on an animated character. We demonstrate the value of these metrics by applying them to the problems of parametrisation, level-of-detail (LOD) and frustum culling. These metrics provide information about the entire range of poses of an animated character, so they are able to produce better results than considering only a single pose of the character, as is commonly done.
In order to compute parametrisations, it is necessary to segment the mesh into charts. We apply an existing algorithm based on greedy merging, but use a metric better suited to the problem than the one suggested by the original authors. To combine the parametrisations with level-of-detail, we require the charts to have straight edges. We explored a heuristic approach to straightening the edges produced by the automatic algorithm, but found that manual segmentation produced better results. Animation space is nevertheless beneficial in flattening the segmented charts; we use least squares conformal maps (LSCM), with the Euclidean distance metric replaced by one of our animation-space metrics. The resulting parametrisations have significantly less overall stretch than those computed based on a single pose.
Similarly, we adapt appearance preserving simplification (APS), a progressive mesh-based LOD algorithm, to apply to animated characters by replacing the Euclidean metric with an animation-space metric. When using the memoryless form of APS (in which local rather than global error is considered), the use of animation space for computations reduces the geometric errors introduced by LOD decomposition, compared to simplification based on a single pose. User tests, in which users compared video clips of the two, demonstrated a statistically significant preference for the animation-space simplifications, indicating that the visual quality is better as well. While other methods exist to take multiple poses into account, they are based on a sampling of the pose space, and the computational cost scales with the number of samples used. In contrast, our method is analytic and uses samples only to gather statistics.
The quality of LOD approximations by improved further by introducing a novel approach to LOD, influence simplification, in which we remove the influences of bones on vertices, and adjust the remaining influences to approximate the original vertex as closely as possible. Once again, we use an animation-space metric to determine the approximation error. By combining influence simplification with the progressive mesh structure, we can obtain further improvements in quality: for some models and at some detail levels, the error is reduced by an order of magnitude relative to a pure progressive mesh. User tests showed that for some models this significantly improves quality, while for others it makes no significant difference.
Animation space is a generalisation of skeletal subspace deformation (SSD), a popular method for real-time character animation. This means that there is a large existing base of models that can immediately benefit from the modified algorithms mentioned above. Furthermore, animation space almost entirely eliminates the well-known shortcomings of SSD (the so-called “candy-wrapper” and “collapsing elbow” effects). We show that given a set of sample poses, we can fit an animation-space model to these poses by solving a linear least-squares problem.
Finally, we demonstrate that animation space is suitable for real-time rendering, by implementing it, along with level-of-detail rendering, on a PC with a commodity video card. We show that although the extra degrees of freedom make the straightforward approach infeasible for complex models, it is still possible to obtain high performance; in fact, animation space requires fewer basic operations to transform a vertex position than SSD. We also consider two methods of lighting LOD-simplified models using the original normals: tangent-space normal maps, an existing method that is fast to render but does not capture dynamic structures such as wrinkles; and tangent maps, a novel approach that encodes animation-space tangent vectors into textures, and which captures dynamic structures. We compare the methods both for performance and quality, and find that tangent-space normal maps are at least an order of magnitude faster, while user tests failed to show any perceived difference in quality between them.
Models¶
The animation-space models used for testing are available below. The custom
file format is described here.
The files are further compressed with bzip2. The cyberdemon model is omitted
for copyright reasons. Please refer to the thesis for a description of where the models come
from.
The models include LOD records, computed using animation-space APS and influence simplification.
The cylinder video briefly demonstrates the project. It shows a bendy tube, and two ways of simplifying it. In the first half of the video, a naïve algorithm is used that doesn’t consider the joint in the tube, and how badly things can go wrong. In the second half, a smarter algorithm is used that takes the joint into account. The other videos show 100 copies of the model under animation, and were used in user testing. A small amount of LOD is in use (nominal tolerance of 1.5 pixels).
Software¶
You can download the source code
for the tools I developed during my thesis. This includes a collection of C++
tools for manipulating models in various ways, a renderer, and assorted scripts
for Blender. See the file README in the tarball for more information.
You can also download a Blender script that applies Catmull-Clark subdivision to a
mesh, while preserving seams and vertex groups. It currently still has
limitations (in particular, creases are ignored). Blender 2.41 is required (I
haven’t tested it on recent Blender versions, so it might not work at all).
Papers — other¶
Performance Analysis of Sandboxes for Reactive Tasks¶
Bruce Merry. Performance Analysis of Sandboxes for Reactive Tasks. Olympiads in Informatics, Vol 4 (2010), pages 87–94.
Abstract¶
Security mechanisms for programming contests introduce some overhead into time measurements. When large numbers of system calls are made, as is common in reactive tasks with processes communicating over pipes, this may significantly distort timing results. We compared the performance and consistency of two sandboxes based on different security mechanisms. We found that in-kernel security has negligible effect on measured run-times, while ptrace-based security can add overhead of around 75%. We also found that ptrace-based security on a dual-core CPU adds far greater overhead as well as producing highly variable results unless CPU affinity is used.
Using a Linux Security Module for contest security¶
Bruce Merry. Using a Linux Security Module for contest security. Olympiads in Informatics, Vol 3 (2009), pages 67–73.
Abstract¶
The goal of a programming contest grading system is to take unknown code and execute it on test data. Since the code is frequently buggy and potentially malicious, it is necessary to run the code in a restricted environment to prevent it from damaging the grading system, bypassing resource constraints, or stealing information in order to obtain a better score.
We present some background on methods to construct such a restricted environment. We then describe how the South African Computer Olympiad has used a Linux Security Module to implement a restricted environment, as well as the limitations of our solution.
Challenges in Running a Computer Olympiad in South Africa¶
Bruce Merry, Marco Gallotta, Carl Hultquist. Challenges in Running a Computer Olympiad in South Africa. Olympiads in Informatics, Vol 2 (2008), pages 105–114.
Abstract¶
Information and Communication Technology (ICT) in South Africa lags behind that of the developed world, which poses challenges in running the South African Computer Olympiad (SACO). We present the three-round structure of the SACO as it is run today, focusing on the challenges it faces and the choices we have made to overcome them. We also include a few statistics and some historical background to the Olympiad, and sample questions may be found in the appendix.